

The Evolution of Search Engines: A Comprehensive History
In today’s digital age, search engines have become an integral part of our lives, helping us find answers to our questions, discover new information, and connect with the world. But have you ever wondered how these sophisticated tools came into existence? The history of search engines is a fascinating journey through innovation, competition, and technological advancements. In this article, we’ll delve into the evolution of search engines, from their humble beginnings to their dominant role in our online experiences.
The Precursors to Modern Search Engines
Before we dive into the history of modern search engines, it’s essential to acknowledge their precursors. These early information retrieval systems paved the way for the sophisticated search engines we use today.
- Librarians and Card Catalogs: Long before the internet, librarians were the human search engines of their time. Libraries used card catalogs, which were essentially physical databases of books and resources. To find a specific book, you’d approach a librarian who would search through these catalogs to provide you with the information you needed.
- Directories and Indexes: Directories and indexes, like the Yellow Pages, served as essential resources for finding businesses and services. These publications organized information by category and were frequently used for location-based searches.
- Early Online Databases: As the internet started to take shape, early online databases, such as Gopher and Archie, emerged. These systems allowed users to search for files and documents on the early web. However, their scope was limited compared to what we have today.
The Birth of Web Search Engines
The true history of search engines as we know them began with the advent of the World Wide Web in the early 1990s. As the internet expanded rapidly, the need for effective search tools became evident.
- Excite, Lycos, and Yahoo: In the early ’90s, search engines like Excite, Lycos, and Yahoo were introduced. These were some of the first web search engines that used directories and keyword-based searching to help users find information online. Yahoo, in particular, was a pioneer in web directories and became a popular choice for web users.
- AltaVista and the Birth of Full-Text Search: AltaVista, launched in 1995, was a game-changer. It introduced the concept of full-text search, allowing users to search for words within the content of web pages, not just in titles and descriptions. This was a significant leap forward in the accuracy and relevance of search results.
- Google: A Game-Changer in Search: In 1998, two Stanford University students, Larry Page and Sergey Brin, founded Google. Their revolutionary approach to search, based on the PageRank algorithm, quickly made Google the dominant player in the field. Google’s emphasis on backlinks and the authority of web pages significantly improved search quality.
The future holds for search engines and the role they will play in our lives. One thing is certain: the history of search engines is a testament to human ingenuity and our insatiable desire for knowledge in the digital age.
The Rise of Search Engines
1) Archie Search Engine (10 Sep 1990)
Pre-Web Content Search Engine: The Archie search engine, created by Alan Emtage, computer science student at McGill University in Montreal, goes live. The program downloads the directory listings of all the files located on public anonymous FTP (File Transfer Protocol) sites, creates a searchable database of a lot of file names; however, Archie does not index the contents of these sites since the amount of data is so limited it can be readily searched manually.
Working Model:
- FTP Server Indexing: Archie was designed to crawl and index files stored on FTP servers. FTP servers were commonly used to host files and documents, and many universities and organizations had these servers for sharing data.
- Periodic Crawling: Archie had a list of known FTP servers that it would periodically connect to and search for file listings. It would initiate connections to these servers using predefined search criteria.
- File Listings: When Archie connected to an FTP server, it would request the directory listings of files available on that server. These listings included information about the files’ names, sizes, and locations.
- Indexing: Archie would parse and organize the file listings into a searchable database. This database allowed users to search for specific files based on keywords, file names, or other criteria.
- User Queries: Users could access Archie through a command-line interface or text-based menu system. They would enter their search queries, specifying keywords, file types, or other search parameters.
- Search Results: Archie would search its database for files matching the user’s query and return a list of FTP servers and file paths where those files could be found.
- FTP Download: Users could then use an FTP client to connect to the listed servers and download the files they were interested in.
Advantage:
- Specialized File Search: Archie was one of the first search engines to specialize in searching for files on FTP servers. This made it a valuable resource for users looking to find and download specific files, such as software, documents, or multimedia content.
- Efficiency: In the early days of the internet, when bandwidth was limited, Archie’s text-based interface and focus on indexing FTP servers made it an efficient way to find files without the need to browse through countless directories manually.
- Useful for Academia: Universities and research institutions found Archie particularly useful for sharing academic and research-related files, which could be accessed by students and researchers worldwide.
- No Web Page Clutter: Unlike modern web search engines, Archie didn’t index web pages, which meant users didn’t have to sift through irrelevant web content when searching for specific files.
Disadvantage:
- Limited Scope: Archie’s main limitation was its narrow scope. It focused exclusively on FTP servers and didn’t index the World Wide Web or other internet resources. As the web grew in popularity, Archie’s usefulness diminished.
- Complexity: Archie’s command-line interface and text-based menus were not very user-friendly for the average internet user. It required some technical knowledge to use effectively.
- Inadequate Search Capabilities: Archie’s search capabilities were basic compared to modern search engines. It relied primarily on file names and metadata for searches, which could result in imprecise or incomplete results. It didn’t support advanced features like full-text search.
- Limited Content: It only indexed files stored on FTP servers, excluding other important internet resources like web pages, multimedia content, and databases.
- Dependence on Server Availability: The quality of Archie’s search results depended on the availability and indexing practices of the FTP servers it connected to. If a server was down or not well-maintained, it could lead to incomplete or outdated results.
In summary, Archie was a pioneering search tool with advantages related to specialized file search and efficiency in the early internet era. However, it had significant limitations due to its narrow scope, limited search capabilities, and the emergence of more versatile web search engines.
2) W3 Catalog Search Engine (02 Sep 1993)
First Web Search Engine: W3 Catalog was an early web search engine, first released on September 2, 1993 by developer Oscar Nierstrasz at the University of Geneva. The engine was initially given the name jughead, but then later renamed. Unlike later search engines, like Aliweb, which attempt to index the web by crawling over the accessible content of web sites, W3 Catalog exploited the fact that many high-quality, manually maintained lists of web resources were already available. W3 Catalog simply mirrored these pages, reformatted the contents into individual entries, and provided a Perl-based front-end to enable dynamic querying.
Working Model:
- Web Page Indexing: The W3 Catalog started by crawling and indexing web pages. It did this by following links from one web page to another. It used a simple algorithm to navigate the web and index the content of web pages.
- Keyword-Based Index: Unlike modern search engines, the W3 Catalog primarily relied on keywords to index web pages. It would identify and record the keywords found on each web page to create an index.
- Manual Submission: Webmasters and website owners could manually submit their site URLs and descriptions to the W3 Catalog for inclusion in its index. This allowed for some control over what content was included.
- Search Queries: Users could access the W3 Catalog through a web interface, where they could enter search queries by typing keywords. The engine would then search its keyword-based index for web pages containing those keywords.
- Results Ranking: The W3 Catalog would return a list of web pages that matched the search query, ordered by relevance. Relevance was determined based on factors like the number of times the keywords appeared on the page.
- Limited Content: The W3 Catalog indexed and searched web pages but did not have the capabilities to search for files, images, or multimedia content. It focused primarily on text-based web pages.
- Manual Maintenance: Since it relied on manual submissions, the catalog required ongoing maintenance by its administrators to keep the index up to date. This was in contrast to modern search engines that continuously crawl the web.
- Limited Query Capabilities: It had basic search capabilities, primarily supporting keyword-based queries. It lacked many of the advanced search features and algorithms that modern search engines use to provide more accurate and relevant results.
Advantage:
- Pioneering the Web Search: W3 Catalog was one of the earliest web search engines and played a vital role in the early days of the World Wide Web, providing users with a way to discover web content when the web was still in its infancy.
- Simple User Interface: It offered a straightforward and easy-to-use web interface, which made it accessible to users who were new to the web and the concept of online searching.
- Controlled Submissions: The manual submission process allowed webmasters and website owners to ensure that their sites were included in the index. This gave some level of control over what content was searchable, particularly in a time when automated web crawling was not as prevalent.
Disadvantage:
- Limited Search Capabilities: W3 Catalog relied primarily on keyword-based indexing, which resulted in less accurate and relevant search results compared to modern search engines that use sophisticated algorithms, including semantic analysis, link analysis, and user behavior patterns.
- Limited Content: It focused mainly on text-based web pages, excluding non-textual content such as images, videos, and other multimedia. This limited its ability to provide a comprehensive view of the web.
- Manual Maintenance: The reliance on manual submissions and maintenance made it challenging to keep the index up to date as the web continued to grow. Modern search engines use automated web crawlers to keep their indexes current.
- Relevance Issues: The ranking of search results was based on the frequency of keyword occurrences, which often resulted in less accurate and less relevant results, as it couldn’t consider factors like the quality or authority of the web pages.
- Competition: As the web evolved, the W3 Catalog faced competition from more advanced search engines like AltaVista, Google, and Yahoo, which used sophisticated algorithms for indexing and ranking web content, providing users with more accurate and useful search results.
In summary, the W3 Catalog was an important early step in web search technology, but it had limitations in terms of search capabilities, content coverage, and maintenance that made it less effective in the long run, especially when compared to the more advanced and automated search engines that followed.
3) JumpStation Search Engine (21 Dec 1993)
First Web Search Engine to use a crawler and indexer: JumpStation was the first WWW search engine that behaved, and appeared to the user, the way current web search engines do. It started indexing on 12 December 1993 and was announced on the Mosaic “What’s New” webpage on 21 December 1993. It was hosted at the University of Stirling in Scotland. It was written by Jonathon Fletcher, from Scarborough, England, who graduated from the University with a first class honours degree in Computing Science in the summer of 1992 and has subsequently been named “father of the search engine”.
Working Model:
- Web Page Crawling: JumpStation operated by manually collecting web pages. Fletcher would select and collect URLs of web pages he found interesting. This was a stark contrast to modern search engines that use automated web crawlers to index the entire web.
- Manual Indexing: Once the web pages were collected, they were indexed manually. Fletcher would read the pages and extract relevant keywords and phrases from the content. This index was quite limited compared to today’s automated and comprehensive indexing systems.
- Keyword Search: Users could then enter a keyword or phrase into the JumpStation search bar. The search engine would then match the user’s query against the manually created index.
- Ranking: JumpStation didn’t have the complex algorithms and ranking systems of modern search engines. Instead, it would return results based on the frequency of the keyword in the manually indexed pages. This resulted in simple keyword matching without sophisticated relevance ranking.
- User Interface: JumpStation had a very basic text-based user interface. Users entered keywords, and the search engine returned a list of URLs that contained those keywords. There were no snippets or previews of the web pages, just the URLs.
- Limitations: Since JumpStation’s index was manually created and limited in scope, it only covered a small portion of the web. This made it less effective than modern search engines, which index billions of web pages and use advanced algorithms to rank results.
- Discontinuation: JumpStation was an early experiment in web search and was never intended to be a comprehensive search engine. It served as a precursor to more advanced search engines that would follow, like AltaVista and Google. As the web grew, manually indexing and searching became impractical, and JumpStation was discontinued.
Advantage:
- Pioneering Effort: JumpStation was one of the first search engines on the web. It laid the foundation for the development of more advanced search engines that would follow.
- Simplicity: JumpStation was easy to use due to its basic text-based interface. Users simply entered keywords, making it accessible to the early web audience.
- Manually Indexed Content: The manually indexed content was carefully selected by the creator, which meant that the search results were somewhat curated, possibly leading to a higher signal-to-noise ratio.
Disadvantage:
- Limited Coverage: JumpStation’s index was small and manually created. It only covered a fraction of the web, making it far less comprehensive than modern search engines. Users had limited access to information.
- Lack of Freshness: The manual indexing process couldn’t keep up with the rapid growth of the web. Consequently, the index quickly became outdated, and users might not find the most current information.
- No Relevance Ranking: JumpStation lacked advanced algorithms for ranking search results. It relied on simple keyword matching, which often led to less relevant search results compared to modern search engines.
- No Automation: Unlike contemporary search engines that use automated web crawlers to continuously index the web, JumpStation’s manual approach was time-consuming and inefficient.
- No Advanced Features: JumpStation lacked features like snippets, filters, or advanced search options that are commonplace in modern search engines, which limited its usefulness for complex queries.
- Obsolete Technology: JumpStation used technology and methods that are now considered obsolete. It was a product of its time and has long been superseded by more sophisticated search engines.
In summary, while JumpStation was an important early contribution to web search, it had significant limitations, especially in terms of coverage, relevance ranking, and the ability to keep up with the ever-expanding web. It served as a starting point for the development of more advanced and effective search engines that we use today.
4) Yahoo! Directory (XX Jan 1993)
New Web Directory: The Yahoo! Directory was a web directory which at one time rivaled DMOZ in size. The directory was Yahoo!’s first offering and started in 1994 under the name Jerry and David’s Guide to the World Wide Web. When Yahoo! changed its main results to crawler-based listings under Yahoo! Search in October 2002. The directory originally offered two options for suggesting websites for possible listing: “Standard”, which was free, and a paid submission process which offered expedited review. “Standard” was dropped, and a non-refundable review fee of $299 ($600 for adult sites) was required when suggesting any website. If listed, the same amount was charged annually.
Working Model:
- Human-Edited Content: Unlike search engines that rely on automated algorithms, the Yahoo Web Directory was primarily human-edited. A team of editors and volunteers manually reviewed and categorized websites submitted by users.
- Category Structure: The directory was organized into a hierarchical structure of categories and subcategories. This structure helped users navigate through different topics and find websites related to their interests.
- Website Submission: Website owners and users could suggest their websites for inclusion in the directory. Each submission went through a review process to ensure it met the directory’s guidelines.
- Categorization: The directory editors assigned each website to one or more categories based on the content and purpose of the site. This categorization made it easier for users to locate relevant websites within specific areas of interest.
- Searching and Browsing: Users could explore the directory by either browsing through categories or by using the search feature. While browsing, they would navigate through categories to find websites. When searching, they could enter keywords to find websites related to specific topics.
- Directory Listings: When users clicked on a directory listing, they would typically see a brief description of the website along with a link to the site itself. The description was often written by the directory editors to provide context and help users determine the relevance of the site.
- No Ranking Algorithms: Unlike search engines, the Yahoo Web Directory did not use ranking algorithms to determine the order of listings. Instead, websites were listed within categories in a relatively static manner, often in alphabetical order or based on the editor’s discretion.
Advantage:
- Human Curation: The human-editing process ensured a level of quality and accuracy in the listings, as editors could evaluate and categorize websites based on their content.
- Structured Organization: The directory’s category structure made it easy for users to explore and discover websites within specific niches or topics.
- Quality Control: The review process helped maintain a certain level of quality and prevented the inclusion of spam or low-quality websites.
Disadvantage:
- Limited Coverage: The directory couldn’t keep up with the rapid growth of the web. As a result, it had limited coverage compared to search engines that indexed a much larger number of web pages.
- Stagnant Listings: The static nature of the directory meant that website listings rarely changed, making it difficult to discover new and updated content.
- Resource-Intensive: Human curation was a time-consuming and resource-intensive process, making it difficult to scale the directory as the web expanded.
The Yahoo Web Directory eventually became less relevant as search engines with automated algorithms, like Google, gained prominence due to their ability to index and rank a much larger portion of the web. Yahoo transitioned to a more search engine-focused approach, but the directory played a significant role in the early days of the web.
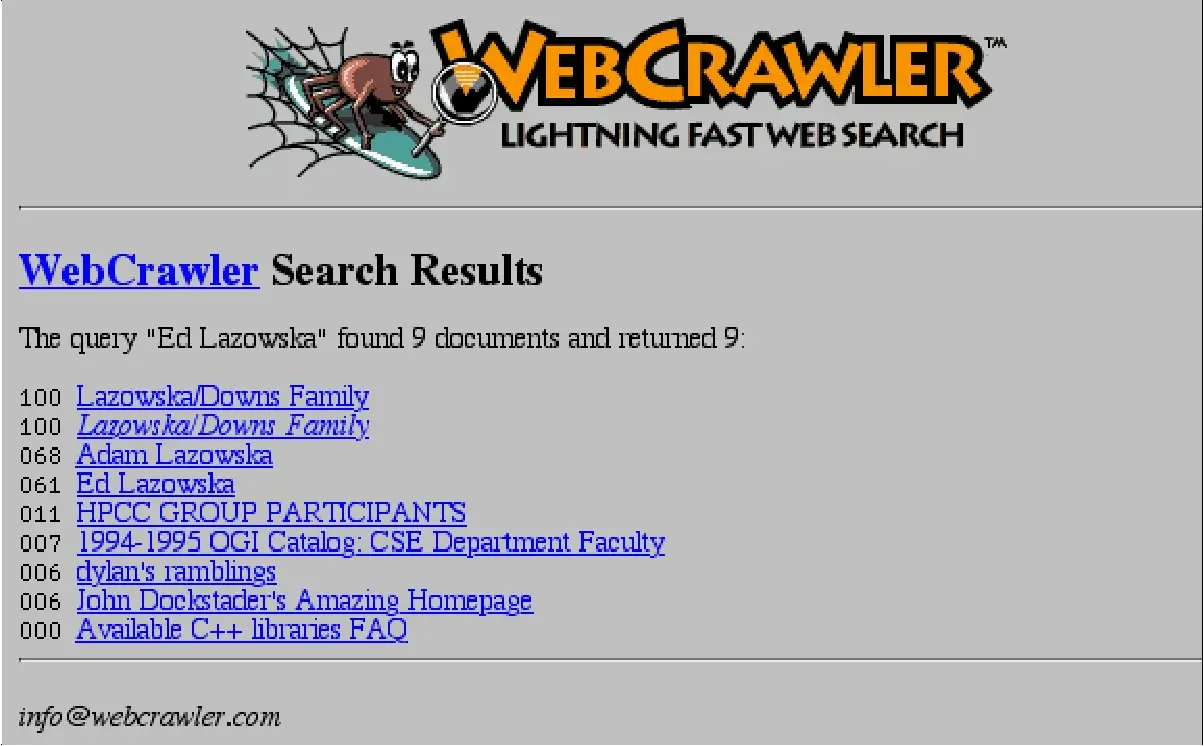
5) WebCrawler Search Engine (21 Apr 1994)
New Web Search Engine: The WebCrawler search engine, created by Brian Pinkerton at the University of Washington, is released. Unlike its predecessors, it allows users to search for any word in any webpage, which has become the standard for all major search engines since. Brian Pinkerton first started working on WebCrawler, which was originally a desktop application, on January 27, 1994 at the University of Washington. On March 15, 1994, he generated a list of the top 25 websites. WebCrawler launched on April 21, 1994, with more than 4,000 different websites in its database and on November 14, 1994, WebCrawler served its 1 millionth search query for “nuclear weapons design and research”.
Working Model:
- Web Crawling: WebCrawler employed automated web crawlers, also known as spiders or bots, to browse and index web pages. These crawlers started by visiting a list of known websites and web pages.
- Page Indexing: When a web crawler visited a web page, it would analyze the content, including text and links, to understand the page’s topic and context. The crawler would then add the page to its index, which is essentially a large database of web page information.
- Keyword Extraction: The web crawler would extract keywords and phrases from the page’s content. This process involved analyzing the text to identify important words and phrases that could later be used for searching.
- Link Analysis: WebCrawler’s crawlers also followed the links on each page to discover new web pages. This helped expand the index and ensure a broad coverage of the web.
- Recrawl Process: WebCrawler periodically revisited web pages to check for updates or changes. This process ensured that the search results remained relatively current.
- User Interface: For users, WebCrawler provided a simple and straightforward interface. Users entered keywords or phrases in the search box, and the search engine would return a list of web pages that matched the query.
- Ranking: WebCrawler used a basic ranking algorithm to order search results. This algorithm considered factors like the frequency of keywords on a page and the presence of keywords in specific page elements (e.g., titles, headings).
Advantage:
- Automated Web Crawling: WebCrawler was one of the early search engines to use automated web crawlers, which allowed it to index a large number of web pages. This automation made it more efficient than manual indexing.
- Keyword-Based Search: WebCrawler introduced the concept of keyword-based search, which was a significant advancement for its time. It simplified the process of finding information on the web by allowing users to enter keywords or phrases.
- Large Index: As one of the pioneering search engines, WebCrawler managed to build a substantial index of web pages, providing users with a relatively broad selection of search results.
Disadvantage:
- Basic Relevance Ranking: WebCrawler’s ranking algorithm was relatively basic, and it didn’t always return the most relevant results for user queries. Users often had to sift through numerous pages to find the information they needed.
- Coverage Limitations: While it had a larger index compared to manually curated web directories, WebCrawler’s coverage was still limited compared to modern search engines like Google. It couldn’t keep up with the rapidly expanding web.
- Staleness: Despite periodic recrawling, web pages could become outdated in the index. This could result in less relevant search results over time, especially for rapidly changing topics or recent events.
- Lack of Advanced Features: WebCrawler lacked many of the advanced features and search options that are commonplace in modern search engines, such as filtering options, personalization, or real-time search.
- User Experience: The user interface and user experience of early search engines like WebCrawler were less user-friendly and intuitive compared to modern search engines.
- Competition: WebCrawler faced intense competition from other emerging search engines, which ultimately led to its decline in popularity and relevance.
In summary, WebCrawler was an important early player in the history of web search engines. It introduced the concept of automated web crawling and keyword-based searching. However, it had limitations in terms of relevance ranking, coverage, and keeping the index up to date. Over time, more sophisticated search engines with advanced algorithms and features surpassed it.
6) Yahoo! Search (02 Mar 1995)
New Web Search Engine: The roots of Search date back to Yahoo! Directory, which was launched in 1994 by Jerry Yang and David Filo, then students at Stanford University. In 1995, they introduced a search engine function, called Yahoo! Search, that allowed users to search Yahoo! Directory. It was the first popular search engine on the Web, despite not being a true Web crawler search engine. They later licensed Web search engines from other companies.
Working Model:
- Crawling: Yahoo Search used automated web crawlers, also known as spiders, to browse the web. These crawlers started by visiting a list of known websites and web pages.
- Indexing: When a crawler visited a web page, it would analyze the content, including text, images, and links. The content and metadata were then added to Yahoo’s search index, which was essentially a massive database of information about web pages.
- Keyword Extraction: The crawlers would extract keywords and phrases from the page’s content and metadata. This process involved analyzing the text to identify important words and phrases that could be used for searching.
- Link Analysis: Yahoo’s crawlers followed the links on each page to discover new web pages. This helped expand the index and ensure a broad coverage of the web.
- User Query Processing: When a user entered a query into Yahoo’s search box, the search engine would process the query and identify keywords and search terms. Yahoo’s system would then search its index for web pages containing those keywords and phrases.
- Relevance Ranking: Yahoo’s search algorithm would rank the search results based on relevance. It considered various factors, such as the frequency and location of keywords on a page, the quality and popularity of the website, and other relevance signals.
- Displaying Search Results: Yahoo would then present the search results to the user, typically in the form of a list of web page titles and brief descriptions, along with links to the web pages.
- Additional Features: Yahoo Search also offered additional features, such as filtering options, search categories, and sponsored search results, which were paid advertisements shown alongside organic search results.

Advantage:
- Comprehensive Directory: Yahoo began as a web directory and evolved into a search engine, which meant it had a well-organized and comprehensive directory of websites and resources. This made it easier for users to find information in various categories.
- Additional Features: Yahoo Search offered a range of features beyond basic search, such as the ability to search for images, videos, news, and more. It also included filters, advanced search options, and a variety of categories to refine search results.
- Integration with Yahoo Services: Yahoo Search was closely integrated with other Yahoo services, including Yahoo Mail and Yahoo News, creating a seamless experience for Yahoo users.
- Sponsored Results: The inclusion of sponsored search results allowed businesses to reach a targeted audience through paid advertising, which was beneficial for both advertisers and the search engine itself.
- Global Presence: Yahoo Search was available in multiple languages and accessible to users around the world, which helped it build a global user base.
Disadvantage:
- Relevance Issues: Yahoo’s search algorithm often struggled to deliver highly relevant results, especially when compared to competitors like Google. This meant users might have to sift through less-relevant results to find what they were looking for.
- Static Index: Yahoo’s index could become outdated, leading to less relevant search results over time. This was a common issue with search engines of its era.
- Lack of Freshness: The search engine sometimes had difficulty keeping up with rapidly changing web content, making it less useful for accessing the most current information.
- Decline in Popularity: Yahoo Search lost popularity to more advanced and user-friendly search engines like Google, which eventually overtook Yahoo as the primary choice for web search.
- Complex User Interface: Yahoo Search’s interface became cluttered over time due to the integration of various Yahoo services, which could make the user experience less intuitive.
- Evolution and Transition: Yahoo transitioned away from being a traditional search engine and focused on other aspects of its business, reducing its competitiveness in the search industry.
In summary, Yahoo Search had several advantages, including a comprehensive directory and integration with other Yahoo services. However, it faced significant challenges related to relevance, maintaining a current index, and keeping up with evolving user expectations. Ultimately, it was surpassed by more advanced search engines, leading to its decline in popularity.
7) Altavista Search Engine (15 Dec 1995)
Web Search Engine supporting natural language queries: This is a first among web search engines in many ways: it has unlimited bandwidth, allows natural language queries, has search tips, and allows people to add or delete their domains in 24 hours. It was a Web search engine established in 1995. It became one of the most-used early search engines, but lost ground to Google and was purchased by Yahoo! in 2003, which retained the brand, but based all AltaVista searches on its own search engine. On July 8, 2013, the service was shut down by Yahoo!, and since then the domain has redirected to Yahoo!’s own search site.
Working Model:
- Web Crawling: AltaVista used automated web crawlers to browse the web and gather information from web pages. These crawlers started by visiting a list of known websites and web pages.
- Indexing: When a crawler visited a web page, it would analyze the content, including text, images, and links. The content and metadata were added to AltaVista’s index, which was a large and continuously updated database of information about web pages.
- Keyword Extraction: AltaVista’s crawlers would extract keywords and phrases from the page’s content and metadata. This process involved analyzing the text to identify important words and phrases for searching.
- Link Analysis: The crawlers followed the links on each page to discover new web pages. This helped expand the index and ensure a comprehensive coverage of the web.
- User Query Processing: When a user entered a query into AltaVista’s search box, the search engine processed the query and identified relevant keywords and search terms. AltaVista’s system then searched its index for web pages containing those keywords and phrases.
- Relevance Ranking: AltaVista used a ranking algorithm to order search results based on relevance. The algorithm considered various factors, such as the frequency of keywords on a page, the location of keywords (e.g., in titles or headings), and the presence of backlinks from other websites.
- Displaying Search Results: AltaVista presented the search results to the user, typically in the form of a list of web page titles and brief descriptions, along with links to the web pages.
- Advanced Search Features: AltaVista was known for offering advanced search features, such as Boolean operators, field-specific searches, and the ability to search for specific file types, which allowed users to fine-tune their queries.

Advantage:
- Advanced Search Features: AltaVista offered a wide range of advanced search features, including Boolean operators, field-specific searches, and file type filtering. These capabilities allowed users to conduct highly specific and targeted searches.
- Comprehensive Index: AltaVista had a substantial index of web pages, providing users with access to a wide array of search results across various topics and niches.
- Link Analysis: AltaVista’s use of link analysis in its ranking algorithm helped identify authoritative and relevant web pages, which could be beneficial for users seeking high-quality information.
- Multilingual Support: AltaVista offered support for multiple languages, making it accessible to a global audience and allowing users to search for content in different languages.
Disadvantage:
- Relevance Challenges: Despite its advanced features, AltaVista’s ranking algorithm did not always deliver the most relevant search results, particularly as the web expanded and became more complex. Users often had to sift through less relevant results.
- Staleness: Like many search engines of its time, AltaVista’s index could become outdated. This led to search results that were not as current or relevant as users desired.
- Competition: AltaVista faced stiff competition from other search engines, most notably Google, which eventually overtook it in popularity due to its superior search algorithms, more accurate relevance ranking, and a cleaner user experience.
- Complexity: While advanced search features were a strength, they could also be a drawback for some users who preferred simpler and more user-friendly search engines. The wide array of options could be overwhelming.
- Decline in Popularity: As a result of the challenges mentioned above and the rise of more effective search engines, AltaVista lost its prominence and popularity in the search engine market.
In summary, AltaVista was an innovative search engine with advanced features and a comprehensive index, but it faced difficulties related to relevance and competition, which led to its eventual decline. Despite its pioneering role in the history of web search, it was ultimately surpassed by more user-friendly and efficient search engines like Google.
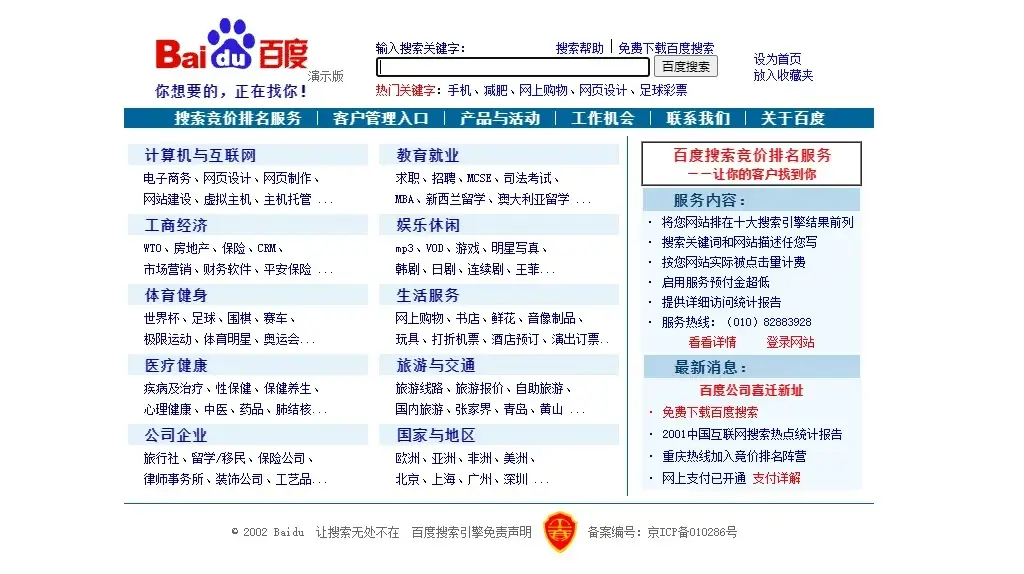
8) RankDex Search Engine (XX XXX 1996)
New Web Search Engine: Robin Li developed the RankDex site-scoring algorithm for search engines results page ranking and received a US patent for the technology. It was the first search engine that used hyperlinks to measure the quality of websites it was indexing,predating the very similar algorithm patent filed by Google two years later in 1998. Larry Page referenced Li’s work as a citation in some of his U.S. patents for PageRank. Li later used his Rankdex technology for the Baidu search engine.
Working Model:
- Page Scoring System: RankDex relied on a page scoring system to rank web pages. Instead of relying solely on content analysis or link analysis, RankDex assigned a numerical score to each web page.
- Link Analysis: RankDex considered the number and quality of links that pointed to a particular web page. High-quality, authoritative links were given more weight in the scoring system.
- User Feedback: It also incorporated user feedback into the ranking process. Users could vote on the relevance and quality of web pages. Pages that received positive user feedback were ranked higher.
- Content Analysis: RankDex analyzed the content of web pages to identify keywords and phrases. It looked at factors such as the frequency and location of keywords on a page to assess its relevance to a given query.
- Page Categorization: RankDex categorized web pages based on their content and relevance to specific topics or themes. This categorization helped users find relevant pages more easily.
- Query Matching: When a user entered a query, RankDex matched it with relevant web pages in its index based on the scoring, link analysis, user feedback, and content analysis.
- Presentation of Search Results: RankDex would then present search results to the user, typically in the form of a list of web page titles and brief descriptions. The ranking of these results was based on the page scores and user feedback.
- Iterative Process: RankDex continuously improved its results by analyzing user interactions. If users clicked on a particular result frequently, it would be given more importance and rank higher in subsequent searches.
Advantage:
- User Feedback Integration: RankDex was one of the early search engines to actively incorporate user feedback into its ranking algorithm, helping to identify high-quality pages.
- Link Analysis: The inclusion of link analysis and the evaluation of link quality helped identify authoritative and relevant pages.
- Content Analysis: By analyzing the content of web pages, RankDex assessed relevance more accurately.
Disadvantage:
- Complex Algorithm: The scoring system and user feedback integration made RankDex’s ranking algorithm complex and potentially harder to fine-tune for optimal results.
- Resource-Intensive: The integration of user feedback and frequent revaluation of results required significant resources and server capacity.
- Limited Scale: RankDex’s approach may have been less scalable and harder to apply to the vast and rapidly growing web, which could limit its coverage.
- Evolution and Transition: Over time, RankDex evolved into Baidu, which adopted different search technologies to compete in the evolving search engine market.
In summary, RankDex was innovative in its approach, particularly in incorporating user feedback and link analysis into the ranking process. It laid the foundation for Baidu, one of the leading search engines in China, but was eventually succeeded by more advanced and scalable search engine technologies.
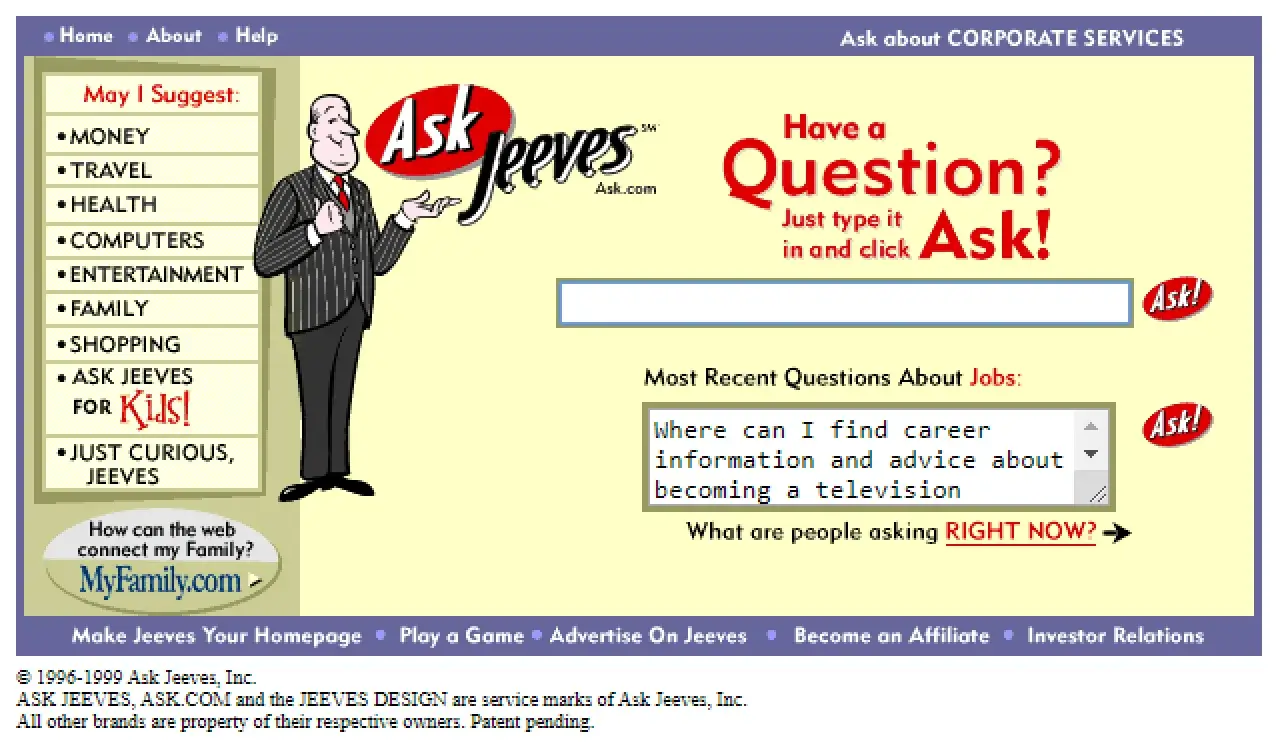
9) Ask Jeeves Search Engine (01 June 1997)
New natural language-based Web Search Engine: Ask Jeeves launched in beta in mid-April 1997 and fully launched on June 1, 1997. On September 18, 2001, Ask Jeeves acquired Teoma for over $1.5 million. In July 2005, Ask Jeeves was acquired by IAC. In February 2006, Jeeves was removed from Ask Jeeves and the search engine rebranded to Ask. “Jeeves” being the name of a “gentleman’s personal gentleman”, or valet, fetching answers to any question asked. The character was named after Jeeves, Bertie Wooster’s valet in the fictional works of P. G. Wodehouse. The original idea behind Ask Jeeves was to allow users to get answers to questions in everyday, natural language, and traditional keyword searching. The current Ask.com still supports this for math, dictionary, and conversion questions.
Working Model:
- Natural Language Queries: One of the distinguishing features of Ask Jeeves was its focus on natural language queries. Users could ask questions in plain, everyday language rather than using specific keywords.
- Semantic Search: Ask Jeeves utilized semantic search technology to understand the meaning behind user queries. It attempted to interpret the context and intent of the questions and provide relevant answers.
- Query Analysis: When a user entered a question, Ask Jeeves analyzed the query to identify important keywords and phrases. It aimed to extract the main concepts and context of the question.
- Structured Data and Directories: Ask Jeeves had a structured data component that included directories and content categorized by subject matter. This helped in providing more specific and accurate results for certain queries.
- Answer Retrieval: After understanding the user’s query, Ask Jeeves would search its index and structured directories for web pages or sources that contained relevant answers or information.
- Natural Language Processing: Ask Jeeves employed natural language processing (NLP) techniques to understand and generate responses to user queries in a conversational manner.
- Question-Answer Pairs: The search engine attempted to match user questions with specific question-answer pairs in its database. These pairs were created by human editors and were designed to provide accurate and concise responses.
- Displaying Results: Ask Jeeves would present search results to the user, including a list of web page titles, brief descriptions, and, in many cases, direct answers to the user’s question.
Advantage:
- User-Friendly: The natural language query format made Ask Jeeves very user-friendly, especially for users who were not familiar with using keywords in traditional search engines.
- Structured Information: The inclusion of structured data and directories allowed Ask Jeeves to provide more specific and accurate results for certain types of queries.
- Unique Approach: Ask Jeeves had a unique approach to search by focusing on understanding and answering user questions directly, which set it apart from other search engines.
Disadvantage:
- Limitations in Query Interpretation: While it excelled at simple and straightforward queries, Ask Jeeves sometimes struggled to interpret more complex or ambiguous questions accurately.
- Coverage and Freshness: It faced challenges in terms of the size of its index and the ability to provide the most up-to-date information compared to larger search engines like Google.
- Shift in Strategy: Over time, Ask Jeeves transitioned to a more traditional keyword-based search engine, moving away from its original question-and-answer format, which might have disappointed some of its users.
In summary, Ask Jeeves (Ask.com) was known for its user-friendly, natural language query approach and its unique focus on answering questions directly. However, it eventually shifted its strategy to compete with other search engines, moving away from its distinctive question-and-answer format.
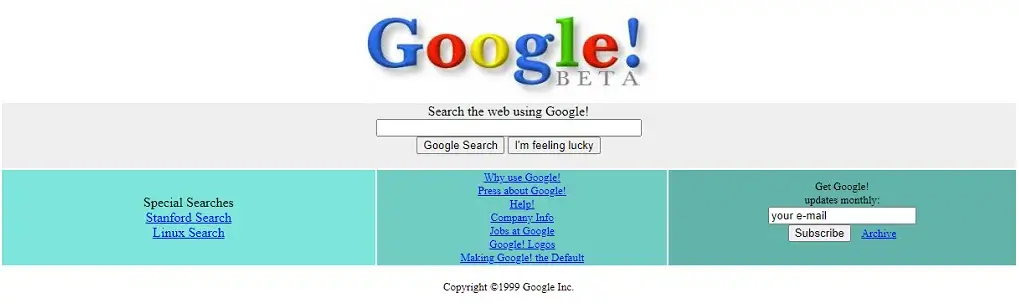
10) Google Search Engine (04 Sep 1998)
New Web Search Engine: Google was founded on September 4, 1998, by American computer scientists Larry Page and Sergey Brin while they were PhD students at Stanford University in California. Together they own about 14% of its publicly listed shares and control 56% of its stockholder voting power through super-voting stock. The company went public via an initial public offering (IPO) in 2004. In 2015, Google was reorganized as a wholly owned subsidiary of Alphabet Inc. Google is Alphabet’s largest subsidiary and is a holding company for Alphabet’s internet properties and interests. Sundar Pichai was appointed CEO of Google on October 24, 2015, replacing Larry Page, who became the CEO of Alphabet. On December 3, 2019, Pichai also became the CEO of Alphabet.
Working Model:
- Web Crawling: Google uses automated web crawlers, often referred to as “Googlebot,” to continuously explore and index web pages. These bots follow links from page to page, discovering new content across the web.
- Page Indexing: When Googlebot visits a web page, it analyzes the page’s content, including text, images, and other media. It then adds the content and metadata to Google’s massive index, a structured and organized database of web pages.
- Ranking Algorithms: Google uses sophisticated ranking algorithms to determine the order in which search results are displayed. One of its most famous algorithms is PageRank, which evaluates the quality and authority of web pages based on the number and quality of links pointing to them.
- Semantic Analysis: Google incorporates semantic analysis to understand the meaning of search queries and the content of web pages. This helps Google match queries to relevant pages and understand user intent.
- User Data Analysis: Google tracks user interactions, such as click-through rates and dwell time (how long a user stays on a page after clicking a search result). This data is used to refine and improve search results.
- Freshness and Recency: Google prioritizes fresh and up-to-date content. It continuously re-crawls web pages to ensure that its index is as current as possible, making it particularly useful for users seeking the latest news and information.
- Personalization: Google offers personalized search results based on a user’s search history and preferences. It may also consider the user’s location and device to tailor results to their specific needs.
- Rich Snippets and Knowledge Graph: Google provides additional information directly in the search results through features like rich snippets (providing structured data like ratings, reviews, and event information) and the Knowledge Graph (a database of facts about people, places, and things).
- Ad Auctions: Google AdWords, now known as Google Ads, allows advertisers to bid on keywords to have their ads displayed alongside organic search results. These paid ads are displayed based on an auction system and the ad’s quality score.
- Natural Language Processing (NLP): Google has improved its understanding of natural language over time, making it more adept at interpreting and responding to complex queries, especially with the integration of the BERT algorithm.
Advantage:
- Relevance: Google is known for providing highly relevant search results, thanks to its advanced ranking algorithms and continuous improvements in understanding user intent.
- Comprehensive Index: Google’s index is vast, encompassing billions of web pages, providing users with access to a wide range of information.
- User Experience: Google’s simple and intuitive user interface has made it one of the most user-friendly search engines.
Disadvantage:
- Privacy Concerns: Google’s data collection and user tracking have raised privacy concerns, as it stores a substantial amount of user information to personalize search results and ads.
- Monopoly Concerns: Google’s dominance in the search market has led to concerns about antitrust and competition issues.
- Potential for Bias: The algorithms used by Google have the potential to introduce bias in search results or reinforce filter bubbles, which can limit the diversity of information users are exposed to.
In summary, Google.com works through a combination of web crawling, indexing, complex ranking algorithms, semantic analysis, user data analysis, and personalization to provide users with relevant and up-to-date search results. Its user-friendly interface and continuous innovation have contributed to its status as one of the most widely used search engines in the world.
The Modern Search Engine Landscape
As Google continued to dominate the search engine market, other search engines evolved and adapted to compete. The modern search engine landscape is a diverse ecosystem with several key players.
Microsoft’s Bing: Microsoft entered the search engine market with Bing in 2009. Bing introduced features like “Bing Visual Search” and “Bing Predicts,” aiming to provide a visually rich and predictive search experience.
Yahoo’s Transition: Yahoo, once a prominent search engine, transitioned to a search partnership with Microsoft in 2009, with Bing providing the underlying search technology for Yahoo Search. This partnership aimed to challenge Google’s dominance.
Mobile Search and Voice Assistants: The rise of smartphones brought mobile search to the forefront. Voice-activated assistants like Apple’s Siri, Google Assistant, and Amazon’s Alexa revolutionized how we interact with search engines, enabling voice queries and hands-free searches.
Unveiling the Future: How Search Engines Are Transforming Our World
The history of search engines is marked by continuous evolution and innovation. As we move forward, search engines are expected to become even more personalized, driven by artificial intelligence and machine learning. Predictive search, semantic search, and visual search are just a few of the exciting developments on the horizon.
Conclusion
In conclusion, the journey through the evolution of search engines has taken us on a remarkable technological odyssey. From the humble beginnings of precursors to the internet age, we’ve witnessed the birth and rise of web search engines, each step characterized by innovation and the relentless pursuit of better search experiences. As we stand in the modern search engine landscape, we can appreciate the incredible leaps in technology, algorithms, and user experience that have brought us to this point.
But this evolution is far from over. The future holds promises of transformation that will continue to shape the way we interact with the digital world. With artificial intelligence, voice recognition, and semantic search on the horizon, search engines are poised to become even more intuitive, efficient, and integrated into our daily lives.

{kind=link}